 Publications
Publications
(*: Equal contribution, C: Conference, W: Workshop, P: Preprint)
Note: The list below can be often outdated. An up-to-date version can be found on Google Scholar.
Kyuyoung Kim, Jongheon Jeong, Minyong An, Mohammad Ghavamzadeh, Krishnamurthy Dj Dvijotham, Jinwoo Shin, Kimin Lee
International Conference on Learning Representations (ICLR), 2024
Code
Additional information
Abstract
Fine-tuning text-to-image models using reward functions trained on human feedback data has emerged as a powerful approach for aligning model behavior with human intent. However, excessive optimization with such reward models, which are only proxy objectives, can degrade the performance of the fine-tuned models, a phenomenon commonly referred to as reward overoptimization. We introduce the Text-Image Alignment Assessment (TIA2) benchmark, a diverse collection of text prompts, images, and human annotations, for studying the issue in depth. We evaluate several state-of-the-art reward models for text-to-image generation on our benchmark and find that they are often not well-aligned with human assessment. We empirically demonstrate that overoptimization can occur when a poorly aligned reward model is used as a fine-tuning objective. To address this, we introduce a simple method, TextNorm, for inducing confidence calibration in reward models by normalizing the scores across prompts that are semantically different from the original prompt. We demonstrate that using the confidence-calibrated scores in fine-tuning effectively reduces the risk of overoptimization.
BibTeX
@inproceedings{
kim2024confidenceaware,
title={Confidence-aware Reward Optimization for Fine-tuning Text-to-Image Models},
author={Kyuyoung Kim and Jongheon Jeong and Minyong An and Mohammad Ghavamzadeh and Krishnamurthy Dj Dvijotham and Jinwoo Shin and Kimin Lee},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=Let8OMe20n}
}
Jongheon Jeong, Jinwoo Shin
Neural Information Processing Systems (NeurIPS), 2023
Additional information
Abstract
Along with recent diffusion models, randomized smoothing has become one of a few tangible approaches that offers adversarial robustness to models at scale, e.g., those of large pre-trained models. Specifically, one can perform randomized smoothing on any classifier via a simple "denoise-and-classify" pipeline, so-called denoised smoothing, given that an accurate denoiser is available - such as diffusion models. In this paper, we investigate the trade-off between accuracy and certified robustness of denoised smoothing: for example, we question on which representation of diffusion model would maximize the certified robustness of denoised smoothing. We consider a new objective that aims collective robustness of smoothed classifiers across multiple noise levels at a shared diffusion model, which also suggests a new way to compensate the cost of accuracy in randomized smoothing for its certified robustness. This objective motivates us to fine-tune diffusion model (a) to perform consistent denoising whenever the original image is recoverable, but (b) to generate rather diverse outputs otherwise. Our experiments show that this fine-tuning scheme of diffusion models combined with the multi-scale smoothing enables a strong certified robustness possible at highest noise level while maintaining the accuracy closer to non-smoothed classifiers.
Huiwon Jang*, Jihoon Tack*, Daewon Choi, Jongheon Jeong, Jinwoo Shin
Neural Information Processing Systems (NeurIPS), 2023
Additional information
Abstract
Despite its practical importance across a wide range of modalities, recent advances in self-supervised learning (SSL) have been primarily focused on a few well-curated domains, e.g., vision and language, often relying on their domain-specific knowledge. For example, Masked Auto-Encoder (MAE) has become one of the popular architectures in these domains, but less has explored its potential in other modalities. In this paper, we develop MAE as a unified, modality-agnostic SSL framework. In turn, we argue meta-learning as a key to interpreting MAE as a modality-agnostic learner, and propose enhancements to MAE from the motivation to jointly improve its SSL across diverse modalities, coined MetaMAE as a result. Our key idea is to view the mask reconstruction of MAE as a meta-learning task: masked tokens are predicted by adapting the Transformer meta-learner through the amortization of unmasked tokens. Based on this novel interpretation, we propose to integrate two advanced meta-learning techniques. First, we adapt the amortized latent of the Transformer encoder using gradient-based meta-learning to enhance the reconstruction. Then, we maximize the alignment between amortized and adapted latents through task contrastive learning which guides the Transformer encoder to better encode the task-specific knowledge. Our experiment demonstrates the superiority of MetaMAE in the modality-agnostic SSL benchmark (called DABS), significantly outperforming prior baselines.
Subin Kim*, Kyungmin Lee*, June Suk Choi, Jongheon Jeong, Kihyuk Sohn, Jinwoo Shin
Neural Information Processing Systems (NeurIPS), 2023
- Also appeared at ICML SPIGM Workshop 2023
Additional information
Abstract
Generative priors of large-scale text-to-image diffusion models enable a wide range of new generation and editing applications on diverse visual modalities. However, when adapting these priors to complex visual modalities, often represented as multiple images (e.g., video), achieving consistency across a set of images is challenging. In this paper, we address this challenge with a novel method, Collaborative Score Distillation (CSD). CSD is based on the Stein Variational Gradient Descent (SVGD). Specifically, we propose to consider multiple samples as “particles” in the SVGD update and combine their score functions to distill generative priors over a set of images synchronously. Thus, CSD facilitates seamless integration of information across 2D images, leading to a consistent visual synthesis across multiple samples. We show the effectiveness of CSD in a variety of tasks, encompassing the visual editing of panorama images, videos, and 3D scenes. Our results underline the competency of CSD as a versatile method for enhancing inter-sample consistency, thereby broadening the applicability of text-to-image diffusion models.
Sangkyung Kwak, Jongheon Jeong, Hankook Lee, Woohyuck Kim, Jinwoo Shin
ICML Workshop on New Frontiers in Adversarial Machine Learning (AdvML), 2023
Additional information
Abstract
Even with a plenty amount of normal samples, anomaly detection has been considered as a challenging machine learning task due to its one-class nature, i.e., the lack of anomalous samples in training time. It is only recently that a few-shot regime of anomaly detection became feasible in this regard, e.g., with a help from large vision-language pre-trained models such as CLIP, despite its wide applicability. In this paper, we explore the potential of large text-to-image generative models in performing few-shot anomaly detection. Specifically, recent text-to-image models have shown unprecedented ability to generalize from few images to extract their common and unique concepts, and even encode them into a textual token to "personalize" the model: so-called textual inversion. Here, we question whether this personalization is specific enough to discriminate the given images from their potential anomalies, which are often, e.g., open-ended, local, and hard-to-detect. We observe that the standard textual inversion is not enough for detecting anomalies accurately, and thus we propose a simple-yet an effective regularization scheme to enhance its specificity derived from the zero-shot transferability of CLIP. We also propose a self-tuning scheme to further optimize the performance of our detection pipeline, leveraging synthetic data generated from the personalized generative model. Our experiments show that the proposed inversion scheme could achieve state-of-the-art results on a wide range of few-shot anomaly detection benchmarks.
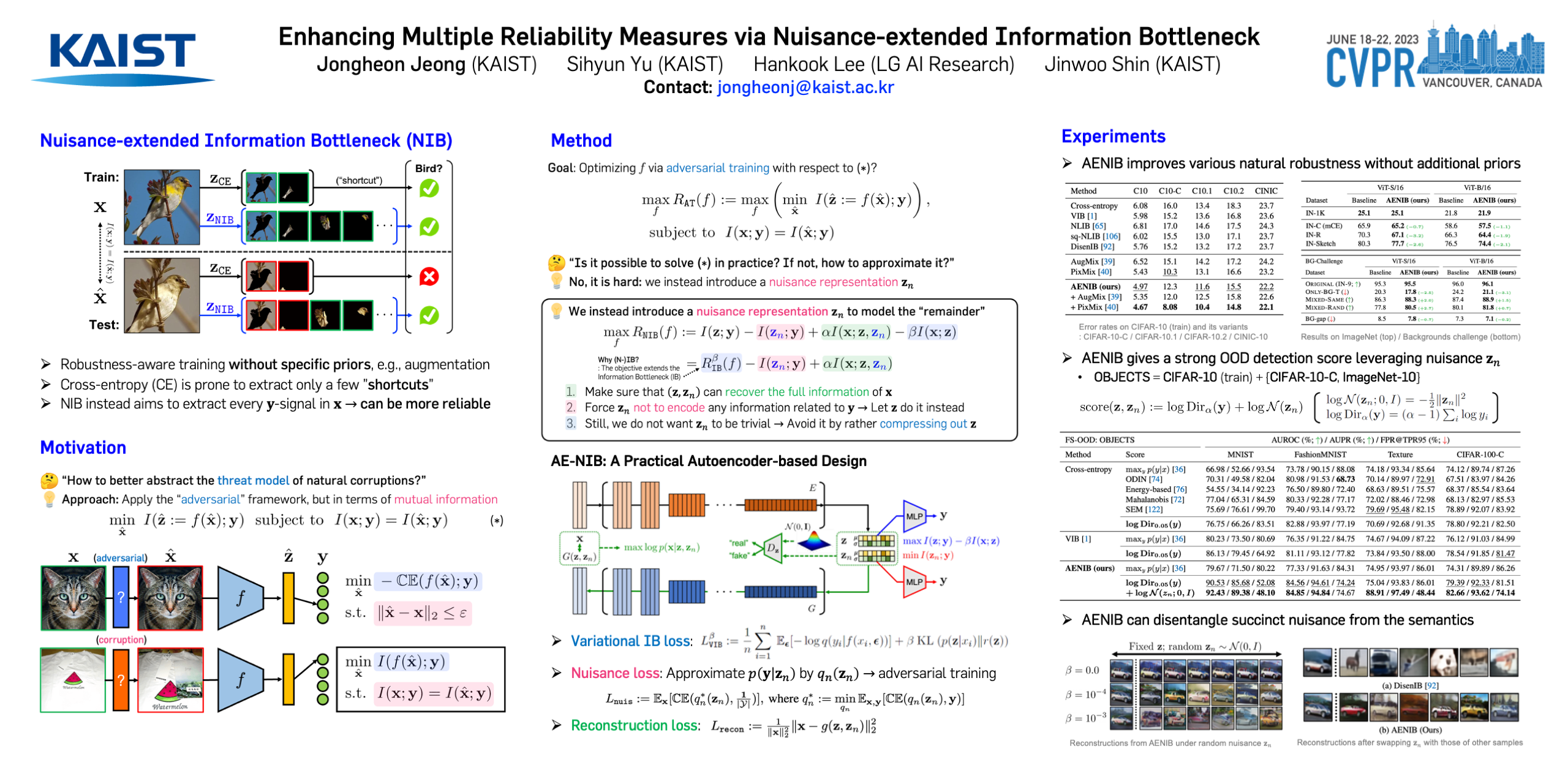
Jongheon Jeong, Sihyun Yu, Hankook Lee, Jinwoo Shin
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
Code
Talk
Slides
Poster
tl;dr: Modeling nuisance information properly can improve out-of-distribution generalization.
- A preliminary version appeared at ECCV OOD-CV Workshop 2022
Additional information
Abstract
In practical scenarios where training data is limited, many predictive signals in the data can be rather from some biases in data acquisition (i.e., less generalizable), so that one cannot prevent a model from co-adapting on such (so-called) "shortcut" signals: this makes the model fragile in various distribution shifts. To bypass such failure modes, we consider an adversarial threat model under a mutual information constraint to cover a wider class of perturbations in training. This motivates us to extend the standard information bottleneck to additionally model the nuisance information. We propose an autoencoder-based training to implement the objective, as well as practical encoder designs to facilitate the proposed hybrid discriminative-generative training concerning both convolutional- and Transformer-based architectures. Our experimental results show that the proposed scheme improves robustness of learned representations (remarkably without using any domain-specific knowledge), with respect to multiple challenging reliability measures including novelty detection, corruption (or natural) robustness and certified adversarial robustness. For example, our model could advance the state-of-the-art on a recent challenging OBJECTS benchmark in novelty detection by 78.4% → 87.2% in AUROC, while simultaneously enjoying improved corruption and certified robustness.
BibTeX
@InProceedings{Jeong_2023_CVPR,
author = {Jeong, Jongheon and Yu, Sihyun and Lee, Hankook and Shin, Jinwoo},
title = {Enhancing Multiple Reliability Measures via Nuisance-Extended Information Bottleneck},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
month = {June},
year = {2023},
pages = {16206-16218}
}
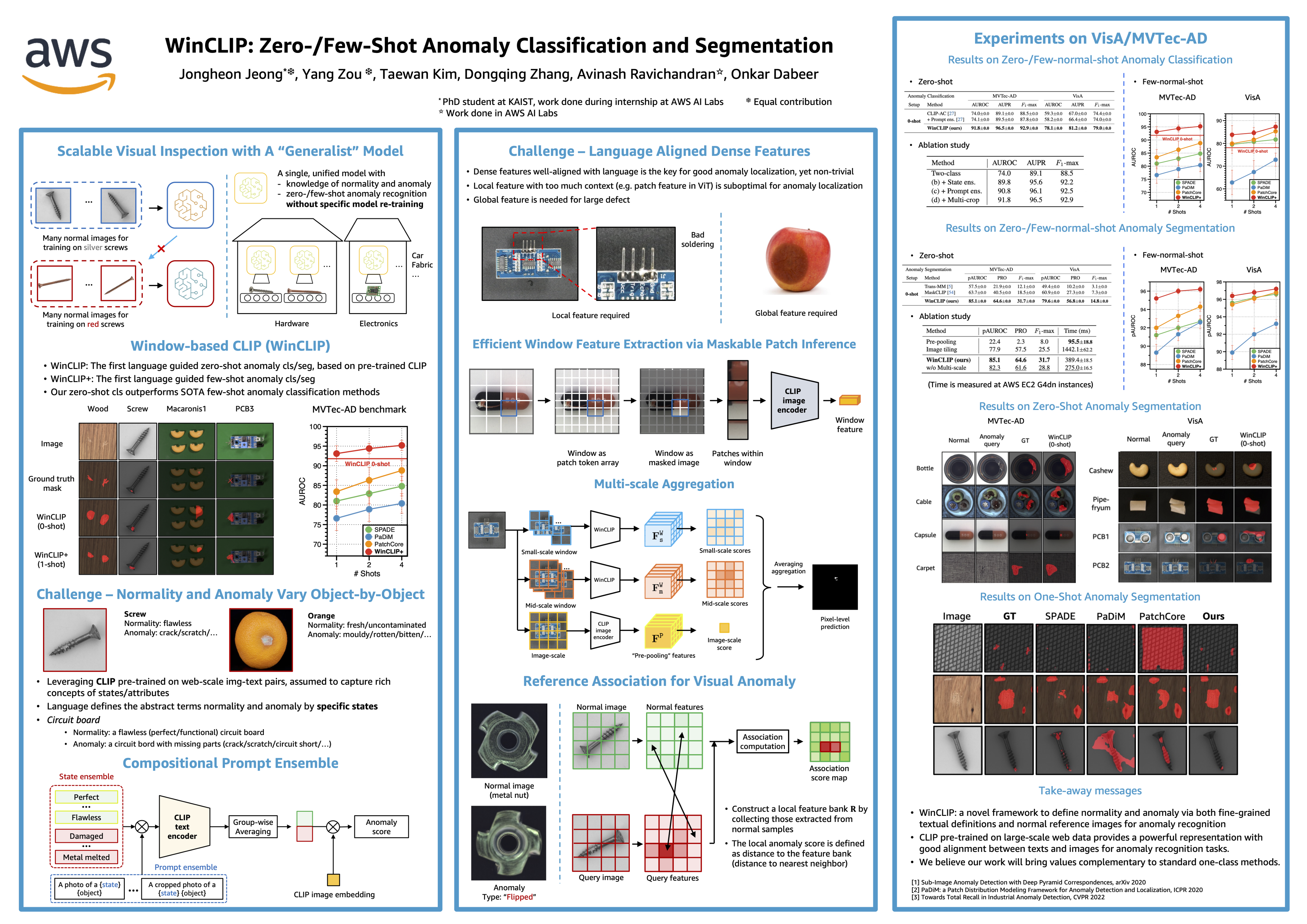
Jongheon Jeong*, Yang Zou*, Taewan Kim, DongQing Zhang, Avinash Ravichandran, Onkar Dabeer
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
Talk
Slides
Poster
tl;dr: State-of-the-art zero-shot and few-shot anomaly recognition via CLIP.
Additional information
Abstract
Visual anomaly classification and segmentation are vital for automating industrial quality inspection. The focus of prior research in the field has been on training custom models for each quality inspection task, which requires task-specific images and annotation. In this paper we move away from this regime, addressing zero-shot and few-normal-shot anomaly classification and segmentation. Recently CLIP, a vision-language model, has shown revolutionary generality with competitive zero/few-shot performance in comparison to full-supervision. But CLIP falls short on anomaly classification and segmentation tasks. Hence, we propose window-based CLIP (WinCLIP) with (1) a compositional ensemble on state words and prompt templates and (2) efficient extraction and aggregation of window/patch/image-level features aligned with text. We also propose its few-normal-shot extension WinCLIP+, which uses complementary information from normal images. In MVTec-AD (and VisA), without further tuning, WinCLIP achieves 91.8%/85.1% (78.1%/79.6%) AUROC in zero-shot anomaly classification and segmentation while WinCLIP+ does 93.1%/95.2% (83.8%/96.4%) in 1-normal-shot, surpassing state-of-the-art by large margins.
BibTeX
@InProceedings{Jeong_2023_CVPR,
author = {Jeong, Jongheon and Zou, Yang and Kim, Taewan and Zhang, Dongqing and Ravichandran, Avinash and Dabeer, Onkar},
title = {Win{CLIP}: Zero-/Few-Shot Anomaly Classification and Segmentation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
month = {June},
year = {2023},
pages = {19606-19616}
}
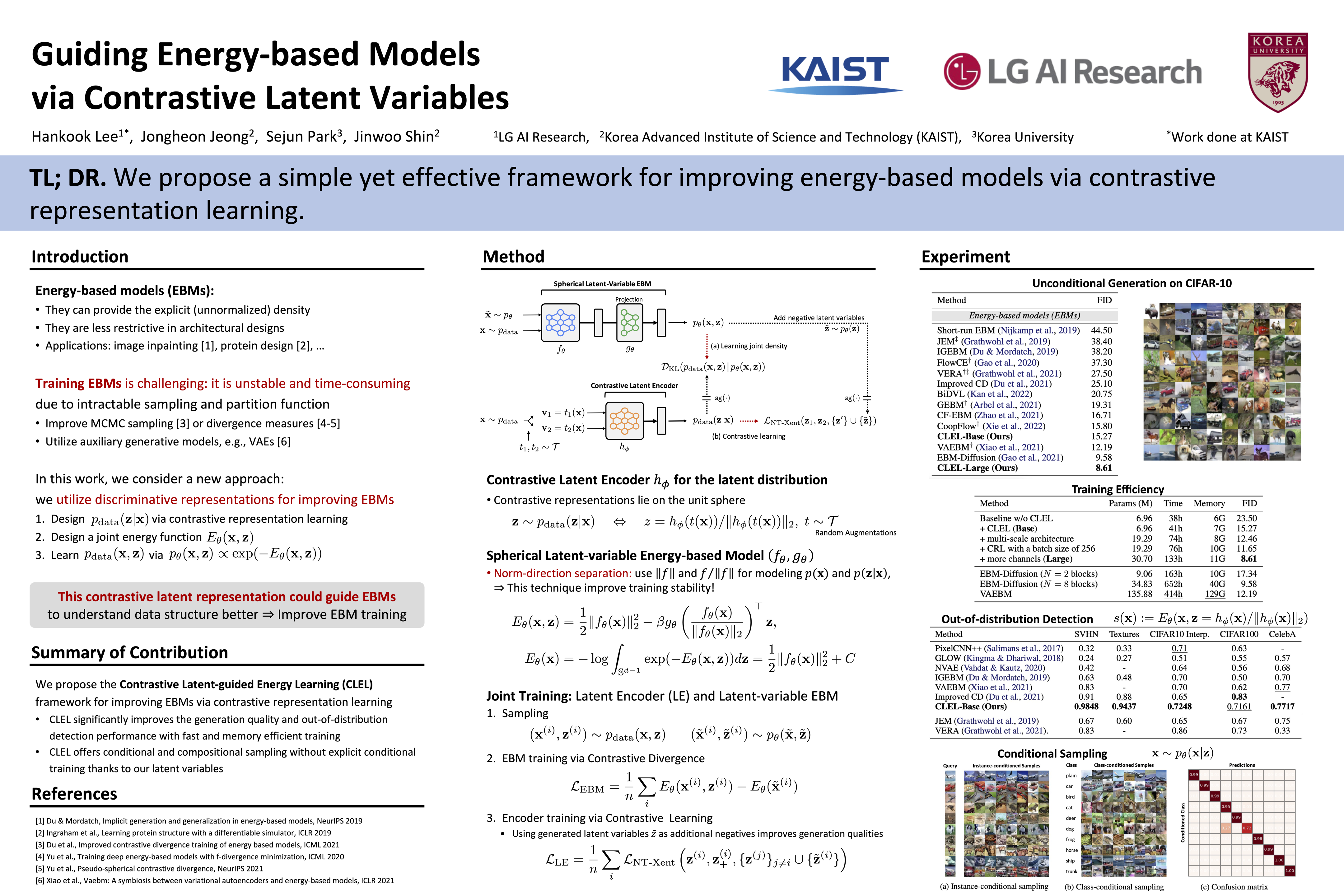
Hankook Lee, Jongheon Jeong, Sejun Park, Jinwoo Shin
International Conference on Learning Representations (ICLR; Spotlight presentation), 2023
Code
Poster
tl;dr: A simple yet effective framework for improving EBMs via contrastive representation learning.
- Also appeared NeurIPS Workshop on Self-Supervised Learning 2022 as an Oral presentation
Additional information
Abstract
An energy-based model (EBM) is a popular generative framework that offers both explicit density and architectural flexibility, but training them is difficult since it is often unstable and time-consuming. In recent years, various training techniques have been developed, e.g., better divergence measures or stabilization in MCMC sampling, but there often exists a large gap between EBMs and other generative frameworks like GANs in terms of generation quality. In this paper, we propose a novel and effective framework for improving EBMs via contrastive representation learning (CRL). To be specific, we consider representations learned by contrastive methods as the true underlying latent variable. This contrastive latent variable could guide EBMs to understand the data structure better, so it can improve and accelerate EBM training significantly. To enable the joint training of EBM and CRL, we also design a new class of latent-variable EBMs for learning the joint density of data and the contrastive latent variable. Our experimental results demonstrate that our scheme achieves lower FID scores, compared to prior-art EBM methods (e.g., additionally using variational autoencoders or diffusion techniques), even with significantly faster and more memory-efficient training. We also show conditional and compositional generation abilities of our latent-variable EBMs as their additional benefits, even without explicit conditional training.
BibTeX
@inproceedings{lee2023guiding,
title={Guiding Energy-based Models via Contrastive Latent Variables},
author={Hankook Lee and Jongheon Jeong and Sejun Park and Jinwoo Shin},
booktitle={International Conference on Learning Representations},
year={2023},
url={https://openreview.net/forum?id=CZmHHj9MgkP}
}
Jongheon Jeong*, Seojin Kim*, Jinwoo Shin
AAAI Conference on Artificial Intelligence (AAAI; Oral presentation), 2023
Code
Slides
Poster
tl;dr: A more sensible training method for randomized smoothing by incorporating a sample-wise control of target robustness.
- Also appeared at ECCV AROW Workshop 2022
Additional information
Abstract
Any classifier can be "smoothed out" under Gaussian noise to build a new classifier that is provably robust to l2-adversarial perturbations, viz., by averaging its predictions over the noise via randomized smoothing. In this paper, we propose a simple training method leveraging the fundamental trade-off between accuracy and (adversarial) robustness to obtain more robust smoothed classifiers, in particular, through a sample-wise control of robustness over the training samples. We make this control feasible by using "accuracy under Gaussian noise" as an easy-to-compute proxy of adversarial robustness for an input: specifically, we differentiate the training objective depending on this proxy to filter out samples that are unlikely to benefit from the worst-case (adversarial) objective. Our experiments show that the proposed method, despite its simplicity, consistently exhibits improved certified robustness upon state-of-the-art training methods. Somewhat surprisingly, we find these improvements persist even for other notions of robustness, e.g., to various types of common corruptions.
BibTeX
@inproceedings{jeong2023catrs,
title={Confidence-aware Training of Smoothed Classifiers for Certified Robustness},
author={Jongheon Jeong and Seojin Kim and Jinwoo Shin},
booktitle={AAAI Conference on Artificial Intelligence},
year={2023}
}
Taesik Gong, Jongheon Jeong, Taewon Kim, Yewon Kim, Jinwoo Shin, Sung-Ju Lee
Neural Information Processing Systems (NeurIPS), 2022
Code
Talk
Poster
tl;dr: The first test-time adaptation method concerning temporally correlated data.
Additional information
Abstract
Test-time adaptation (TTA) is an emerging paradigm that addresses distributional shifts between training and testing phases without additional data acquisition or labeling cost; only unlabeled test data streams are used for continual model adaptation. Previous TTA schemes assume that the test samples are independent and identically distributed (i.i.d.), even though they are often temporally correlated (non-i.i.d.) in application scenarios, e.g., autonomous driving. We discover that most existing TTA methods fail dramatically under such scenarios. Motivated by this, we present a new test-time adaptation scheme that is robust against non-i.i.d. test data streams. Our novelty is mainly two-fold: (a) Instance-Aware Batch Normalization (IABN) that corrects normalization for out-of-distribution samples, and (b) Prediction-balanced Reservoir Sampling (PBRS) that simulates i.i.d. data stream from non-i.i.d. stream in a class-balanced manner. Our evaluation with various datasets, including real-world non-i.i.d. streams, demonstrates that the proposed robust TTA not only outperforms state-of-the-art TTA algorithms in the non-i.i.d. setting, but also achieves comparable performance to those algorithms under the i.i.d. assumption.
BibTeX
@inproceedings{gong2022note,
title={N{OTE}: Robust Continual Test-time Adaptation Against Temporal Correlation},
author={Taesik Gong and Jongheon Jeong and Taewon Kim and Yewon Kim and Jinwoo Shin and Sung-Ju Lee},
booktitle={Advances in Neural Information Processing Systems},
editor={Alice H. Oh and Alekh Agarwal and Danielle Belgrave and Kyunghyun Cho},
year={2022},
url={https://openreview.net/forum?id=E9HNxrCFZPV}
}
Jongjin Park*, Sukmin Yun*, Jongheon Jeong, Jinwoo Shin
ECCV Workshop on Learning from Limited and Imperfect Data (L2ID), 2022
Code
Talk
tl;dr: A contrastive learning based framework to enhance semi-SL methods to also utilize “out-of-class” unlabeled samples.
Additional information
Abstract
Semi-supervised learning (SSL) has been a powerful strategy to incorporate few labels in learning better representations. In this paper, we focus on a practical scenario that one aims to apply SSL when unlabeled data may contain out-of-class samples - those that cannot have one-hot encoded labels from a closed-set of classes in label data, i.e., the unlabeled data is an open-set. Specifically, we introduce OpenCoS, a simple framework for handling this realistic semi-supervised learning scenario based upon a recent framework of self-supervised visual representation learning. We first observe that the out-of-class samples in the open-set unlabeled dataset can be identified effectively via self-supervised contrastive learning. Then, OpenCoS utilizes this information to overcome the failure modes in the existing state-of-the-art semi-supervised methods, by utilizing one-hot pseudo-labels and soft-labels for the identified in- and out-of-class unlabeled data, respectively. Our extensive experimental results show the effectiveness of OpenCoS under the presence of out-of-class samples, fixing up the state-of-the-art semi-supervised methods to be suitable for diverse scenarios involving open-set unlabeled data.
BibTeX
@InProceedings{park2022opencos,
author="Park, Jongjin and Yun, Sukmin and Jeong, Jongheon and Shin, Jinwoo",
title="Open{CoS}: Contrastive Semi-supervised Learning for Handling Open-Set Unlabeled Data",
booktitle="Computer Vision -- ECCV 2022 Workshops",
year="2023",
publisher="Springer Nature Switzerland",
pages="134--149",
isbn="978-3-031-25063-7"
}
Yang Zou, Jongheon Jeong, Latha Pemula, Dongqing Zhang, Onkar Dabeer
European Conference on Computer Vision (ECCV), 2022
Code
Poster
tl;dr: (a) VisA - a new larger-scale benchmark for industrial anomaly detection and segmentation; (b) a novel self-supervised pre-training method targeting anomaly downstream tasks on the benchmark.
Additional information
Abstract
Visual anomaly detection is commonly used in industrial quality inspection. In this paper, we present a new dataset as well as a new self-supervised learning method for ImageNet pre-training to improve anomaly detection and segmentation in 1-class and 2-class 5/10/high-shot training setups. We release the Visual Anomaly (VisA) Dataset consisting of 10,821 high-resolution color images (9,621 normal and 1,200 anomalous samples) covering 12 objects in 3 domains, making it the largest industrial anomaly detection dataset to date. Both image and pixel-level labels are provided. We also propose a new self-supervised framework - SPot-the-difference (SPD) - which can regularize contrastive self-supervised pre-training, such as SimSiam, MoCo and SimCLR, to be more suitable for anomaly detection tasks. Our experiments on VisA and MVTec-AD dataset show that SPD consistently improves these contrastive pre-training baselines and even the supervised pre-training. For example, SPD improves Area Under the Precision-Recall curve (AU-PR) for anomaly segmentation by 5.9% and 6.8% over SimSiam and supervised pre-training respectively in the 2-class high-shot regime. We open-source the project at http://github.com/amazon-research/spot-diff.
BibTeX
@inproceedings{zou2022spot,
title={SPot-the-Difference Self-supervised Pre-training for Anomaly Detection and Segmentation},
author={Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar},
booktitle={European Conference on Computer Vision},
pages={392--408},
year={2022},
organization={Springer}
}
Jihoon Tack, Sihyun Yu, Jongheon Jeong, Minseon Kim, Sung Ju Hwang, Jinwoo Shin
AAAI Conference on Artificial Intelligence (AAAI), 2022
Code
Slides
Poster
tl;dr: Consistency regularization can also prevent robustness overfitting in adversarial training.
- Also appeared ICML AdvML Workshop 2021 as an Oral presentation
- Won the Best Paper Award from Korean Artificial Intelligence Association 2021
Additional information
Abstract
Adversarial training (AT) is currently one of the most successful methods to obtain the adversarial robustness of deep neural networks. However, the phenomenon of robust overfitting, i.e., the robustness starts to decrease significantly during AT, has been problematic, not only making practitioners consider a bag of tricks for a successful training, e.g., early stopping, but also incurring a significant generalization gap in the robustness. In this paper, we propose an effective regularization technique that prevents robust overfitting by optimizing an auxiliary `consistency' regularization loss during AT. Specifically, we discover that data augmentation is a quite effective tool to mitigate the overfitting in AT, and develop a regularization that forces the predictive distributions after attacking from two different augmentations of the same instance to be similar with each other. Our experimental results demonstrate that such a simple regularization technique brings significant improvements in the test robust accuracy of a wide range of AT methods. More remarkably, we also show that our method could significantly help the model to generalize its robustness against unseen adversaries, e.g., other types or larger perturbations compared to those used during training. Code is available at https://github.com/alinlab/consistency-adversarial.
BibTeX
@inproceedings{tack2022consistency,
title={Consistency Regularization for Adversarial Robustness},
author={Jihoon Tack and Sihyun Yu and Jongheon Jeong and Minseon Kim and Sung Ju Hwang and Jinwoo Shin},
booktitle={AAAI Conference on Artificial Intelligence},
year={2022}
}
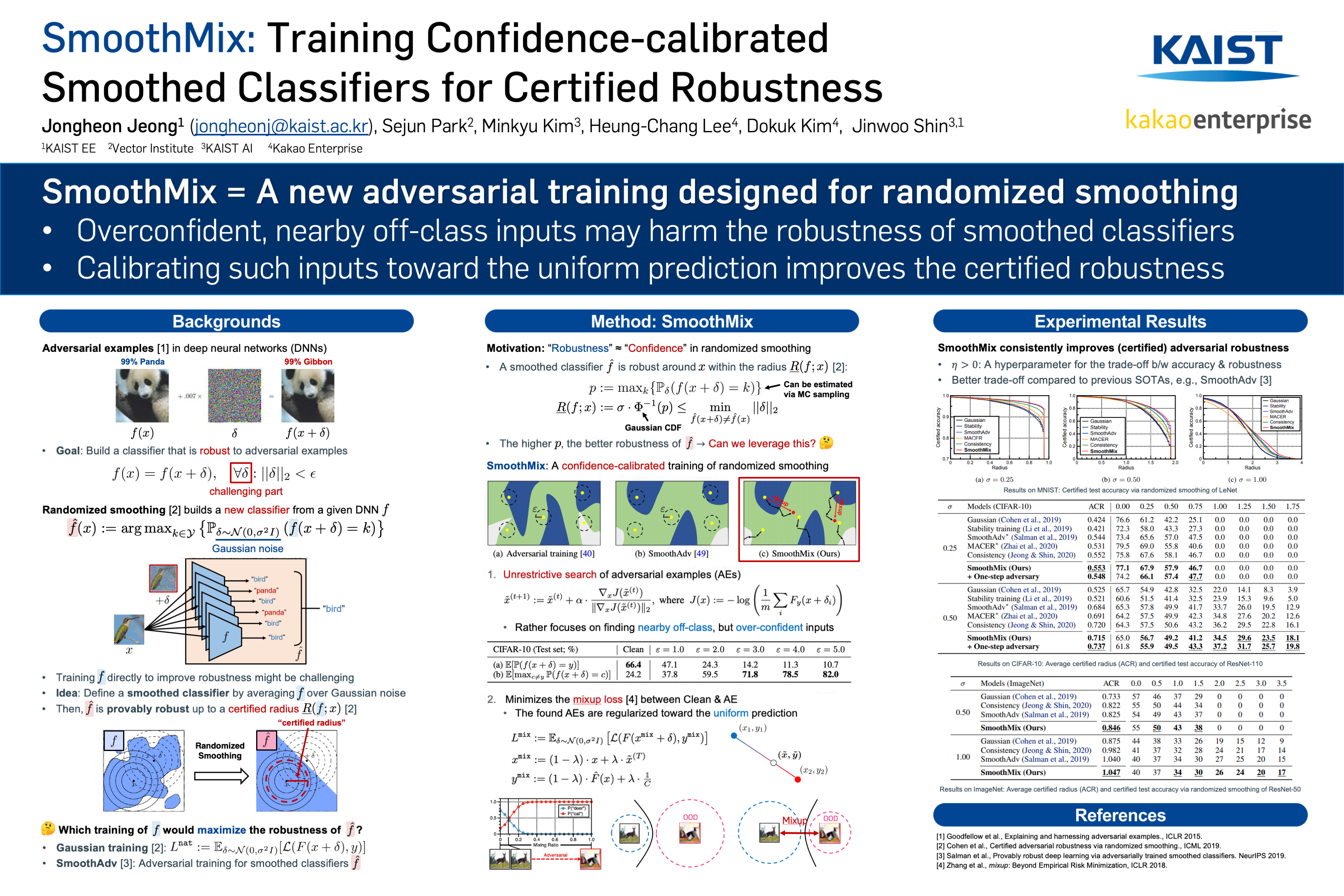
Jongheon Jeong, Sejun Park, Minkyu Kim, Heung-Chang Lee, Doguk Kim, Jinwoo Shin
Neural Information Processing Systems (NeurIPS), 2021
Code
Talk
Slides
Poster
tl;dr: Overconfident inputs nearby the data may cause adversarial vulnerability in randomized smoothing, and regularizing them toward the uniform confidence improves robustness.
- Also appeared at ICML AdvML Workshop 2021
Additional information
Abstract
Randomized smoothing is currently a state-of-the-art method to construct a certifiably robust classifier from neural networks against $\ell_2$-adversarial perturbations. Under the paradigm, the robustness of a classifier is aligned with the prediction confidence, i.e., the higher confidence from a smoothed classifier implies the better robustness. This motivates us to rethink the fundamental trade-off between accuracy and robustness in terms of calibrating confidences of a smoothed classifier. In this paper, we propose a simple training scheme, coined SmoothMix, to control the robustness of smoothed classifiers via self-mixup: it trains on convex combinations of samples along the direction of adversarial perturbation for each input. The proposed procedure effectively identifies over-confident, near off-class samples as a cause of limited robustness in case of smoothed classifiers, and offers an intuitive way to adaptively set a new decision boundary between these samples for better robustness. Our experimental results demonstrate that the proposed method can significantly improve the certified $\ell_2$-robustness of smoothed classifiers compared to existing state-of-the-art robust training methods.
BibTeX
@inproceedings{jeong2021smoothmix,
title={Smooth{Mix}: Training Confidence-calibrated Smoothed Classifiers for Certified Robustness},
author={Jongheon Jeong and Sejun Park and Minkyu Kim and Heung-Chang Lee and Doguk Kim and Jinwoo Shin},
booktitle={Advances in Neural Information Processing Systems},
year={2021},
url={https://openreview.net/forum?id=nlEQMVBD359}
}
Jongheon Jeong, Jinwoo Shin
International Conference on Learning Representations (ICLR), 2021
Code
Talk
Slides
Poster
tl;dr: We propose a novel discriminator of GAN showing that contrastive representation learning, e.g., SimCLR, and GAN can benefit each other when they are jointly trained.
Additional information
Abstract
Recent works in Generative Adversarial Networks (GANs) are actively revisiting various data augmentation techniques as an effective way to prevent discriminator overfitting. It is still unclear, however, that which augmentations could actually improve GANs, and in particular, how to apply a wider range of augmentations in training. In this paper, we propose a novel way to address these questions by incorporating a recent contrastive representation learning scheme into the GAN discriminator, coined ContraD. This "fusion" enables the discriminators to work with much stronger augmentations without increasing their training instability, thereby preventing the discriminator overfitting issue in GANs more effectively. Even better, we observe that the contrastive learning itself also benefits from our GAN training, i.e., by maintaining discriminative features between real and fake samples, suggesting a strong coherence between the two worlds: good contrastive representations are also good for GAN discriminators, and vice versa. Our experimental results show that GANs with ContraD consistently improve FID and IS compared to other recent techniques incorporating data augmentations, still maintaining highly discriminative features in the discriminator in terms of the linear evaluation. Finally, as a byproduct, we also show that our GANs trained in an unsupervised manner (without labels) can induce many conditional generative models via a simple latent sampling, leveraging the learned features of ContraD. Code is available at https://github.com/jh-jeong/ContraD.
BibTeX
@inproceedings{jeong2021training,
title={Training {GAN}s with Stronger Augmentations via Contrastive Discriminator},
author={Jongheon Jeong and Jinwoo Shin},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=eo6U4CAwVmg}
}
Jongheon Jeong, Jinwoo Shin
Neural Information Processing Systems (NeurIPS), 2020
Code
Talk
Slides
Poster
tl;dr: Consistency controls robustness in the world of randomized smoothing, like TRADES in adversarial training.
- Also appeared at ICML UDL Workshop 2020
- Won Qualcomm Innovation Fellowship Korea 2020
Additional information
Abstract
A recent technique of randomized smoothing has shown that the worst-case (adversarial) $\ell_2$-robustness can be transformed into the average-case Gaussian-robustness by "smoothing" a classifier, i.e., by considering the averaged prediction over Gaussian noise. In this paradigm, one should rethink the notion of adversarial robustness in terms of generalization ability of a classifier under noisy observations. We found that the trade-off between accuracy and certified robustness of smoothed classifiers can be greatly controlled by simply regularizing the prediction consistency over noise. This relationship allows us to design a robust training objective without approximating a non-existing smoothed classifier, e.g., via soft smoothing. Our experiments under various deep neural network architectures and datasets show that the "certified" $\ell_2$-robustness can be dramatically improved with the proposed regularization, even achieving better or comparable results to the state-of-the-art approaches with significantly less training costs and hyperparameters.
BibTeX
@inproceedings{jeong2020consistency,
author = {Jeong, Jongheon and Shin, Jinwoo},
booktitle = {Advances in Neural Information Processing Systems},
editor = {H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin},
pages = {10558--10570},
publisher = {Curran Associates, Inc.},
title = {Consistency Regularization for Certified Robustness of Smoothed Classifiers},
url = {https://proceedings.neurips.cc/paper/2020/file/77330e1330ae2b086e5bfcae50d9ffae-Paper.pdf},
volume = {33},
year = {2020}
}
Jihoon Tack*, Sangwoo Mo*, Jongheon Jeong, Jinwoo Shin
Neural Information Processing Systems (NeurIPS), 2020
Code
Talk
Slides
Poster
tl;dr: Contrastive representations are surprisingly good at discriminating OOD samples, and contrasting also “OOD-like” augmentations can further improve their performances.
- Won Qualcomm Innovation Fellowship Korea 2020
Additional information
Abstract
Novelty detection, i.e., identifying whether a given sample is drawn from outside the training distribution, is essential for reliable machine learning. To this end, there have been many attempts at learning a representation well-suited for novelty detection and designing a score based on such representation. In this paper, we propose a simple, yet effective method named contrasting shifted instances (CSI), inspired by the recent success on contrastive learning of visual representations. Specifically, in addition to contrasting a given sample with other instances as in conventional contrastive learning methods, our training scheme contrasts the sample with distributionally-shifted augmentations of itself. Based on this, we propose a new detection score that is specific to the proposed training scheme. Our experiments demonstrate the superiority of our method under various novelty detection scenarios, including unlabeled one-class, unlabeled multi-class and labeled multi-class settings, with various image benchmark datasets. Code and pre-trained models are available at https://github.com/alinlab/CSI.
BibTeX
@inproceedings{tack2020csi,
author = {Tack, Jihoon and Mo, Sangwoo and Jeong, Jongheon and Shin, Jinwoo},
booktitle = {Advances in Neural Information Processing Systems},
editor = {H. Larochelle and M. Ranzato and R. Hadsell and M.F. Balcan and H. Lin},
pages = {11839--11852},
publisher = {Curran Associates, Inc.},
title = {CSI: Novelty Detection via Contrastive Learning on Distributionally Shifted Instances},
url = {https://proceedings.neurips.cc/paper/2020/file/8965f76632d7672e7d3cf29c87ecaa0c-Paper.pdf},
volume = {33},
year = {2020}
}
Jaehyung Kim*, Jongheon Jeong*, Jinwoo Shin
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Code
Talk
Slides
tl;dr: Adversarial examples targeting Majority -> minority can play as surprisingly effective minority samples to prevent overfitting under class-imbalance.
Additional information
Abstract
In most real-world scenarios, labeled training datasets are highly class-imbalanced, where deep neural networks suffer from generalizing to a balanced testing criterion. In this paper, we explore a novel yet simple way to alleviate this issue by augmenting less-frequent classes via translating samples (e.g., images) from more-frequent classes. This simple approach enables a classifier to learn more generalizable features of minority classes, by transferring and leveraging the diversity of the majority information. Our experimental results on a variety of class-imbalanced datasets show that the proposed method improves the generalization on minority classes significantly compared to other existing re-sampling or re-weighting methods. The performance of our method even surpasses those of previous state-of-the-art methods for the imbalanced classification.
BibTeX
@InProceedings{kim2020M2m,
author = {Kim, Jaehyung and Jeong, Jongheon and Shin, Jinwoo},
title = {M2m: Imbalanced Classification via Major-to-Minor Translation},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition},
month = {June},
year = {2020}
}
Jongheon Jeong, Jinwoo Shin
International Conference on Machine Learning (ICML), 2019
Code
Talk
Slides
Poster
tl;dr: Any CNNs can become more efficient by “re-allocating” unnecessary channels to increase the kernel size.
Additional information
Abstract
Recent progress in deep convolutional neural networks (CNNs) have enabled a simple paradigm of architecture design: larger models typically achieve better accuracy. Due to this, in modern CNN architectures, it becomes more important to design models that generalize well under certain resource constraints, e.g. the number of parameters. In this paper, we propose a simple way to improve the capacity of any CNN model having large-scale features, without adding more parameters. In particular, we modify a standard convolutional layer to have a new functionality of channel-selectivity, so that the layer is trained to select important channels to re-distribute their parameters. Our experimental results under various CNN architectures and datasets demonstrate that the proposed new convolutional layer allows new optima that generalize better via efficient resource utilization, compared to the baseline.
BibTeX
@InProceedings{jeong2020training,
title = {Training {CNN}s with Selective Allocation of Channels},
author = {Jeong, Jongheon and Shin, Jinwoo},
booktitle = {Proceedings of the 36th International Conference on Machine Learning},
pages = {3080--3090},
year = {2019},
editor = {Chaudhuri, Kamalika and Salakhutdinov, Ruslan},
volume = {97},
series = {Proceedings of Machine Learning Research},
month = {09--15 Jun},
publisher = {PMLR},
pdf = {http://proceedings.mlr.press/v97/jeong19c/jeong19c.pdf},
url = {https://proceedings.mlr.press/v97/jeong19c.html}
}
Jungtaek Kim, Jongheon Jeong, Seungjin Choi
ICML Workshop on Automatic Machine Learning (AutoML), 2016

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}